

300 дней с AI-агентами: от руководителя к Full Cycle Engineer

Последние 7 лет я руководил командами разработки, но не то что не писал кода — я его даже не читал. В 2025 году я снова вернулся к самостоятельной разработке. И даже могу называть себя Full Cycle Engineer. Что стоит за этим термином — раскрою ниже.
За 2025 год я сделал больше, чем за предыдущие пять лет вместе взятые.
В статье расскажу про проекты, которыми занимался. Про задачи, которые решал. Про выученные уроки, набитые шишки, собранные грабли. И про некоторое количество полезных рабочих процессов и практик, которые у меня сложились и которые делают работу с кодовыми агентами по-настоящему эффективной.
Мой рассказ будет полезен самой широкой аудитории, не только и даже не столько разработчикам, сколько вообще IT-специалистам. И даже тем, кто только присматривается к этой области — благодаря появлению таких инструментов, как AI-агенты.
Немного обо мне
Я в ИТ около 20 лет. Успел поработать на самых разных позициях. Еще в институте начинал как разработчик, был и аналитиком, и продактом, и тимлидом, и руководителем команды, и руководителем нескольких команд. Последние 7 лет руководил командами разработки — и всё это время, конечно, кода не касался.
В 2025 году моя жизнь кардинально изменилась. Все благодаря появлению таких инструментов как кодовые агенты.
В качестве небольшого подтверждения масштабности личных изменений приведу статистику использования Cursor и GitHub.
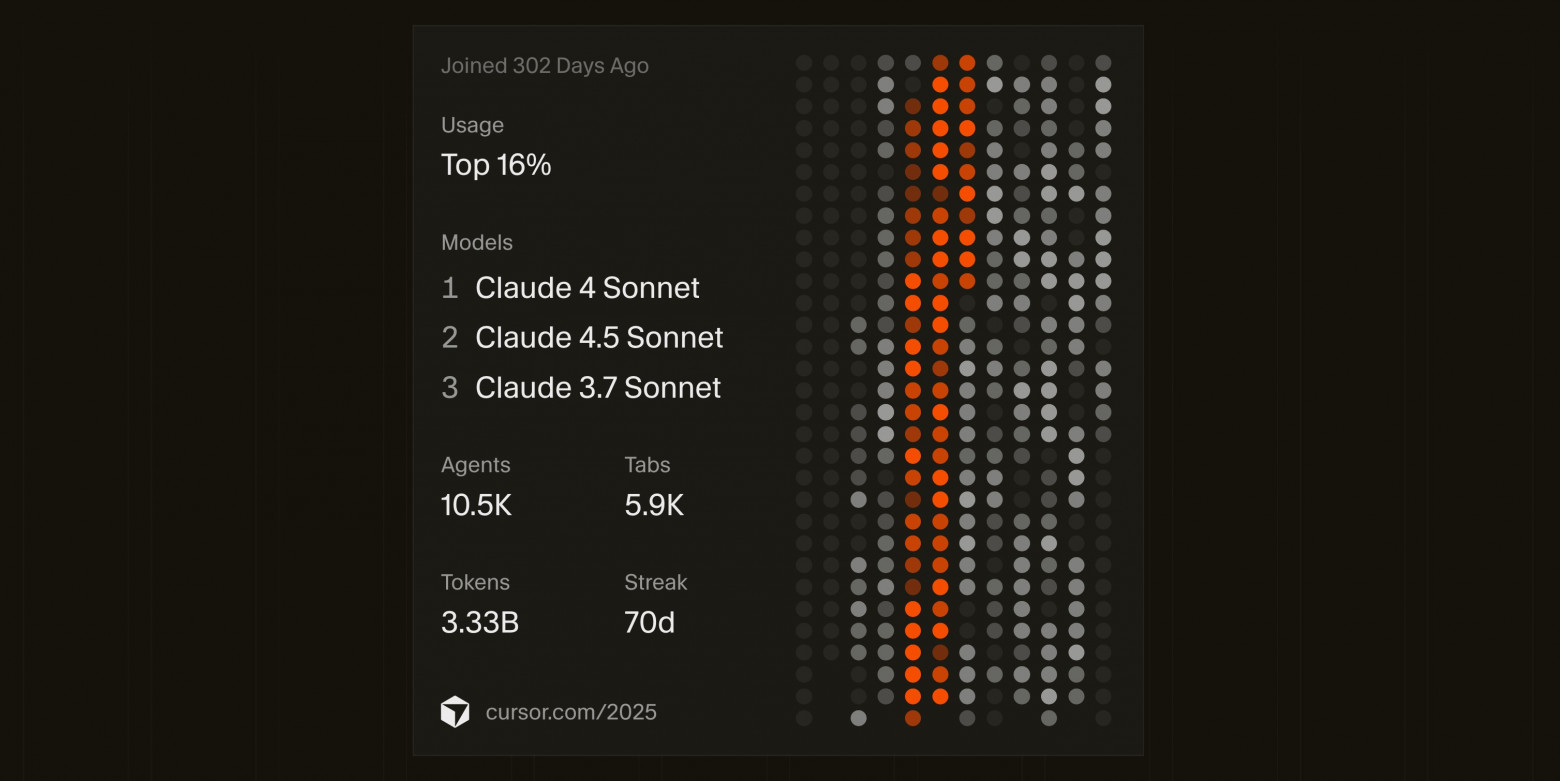
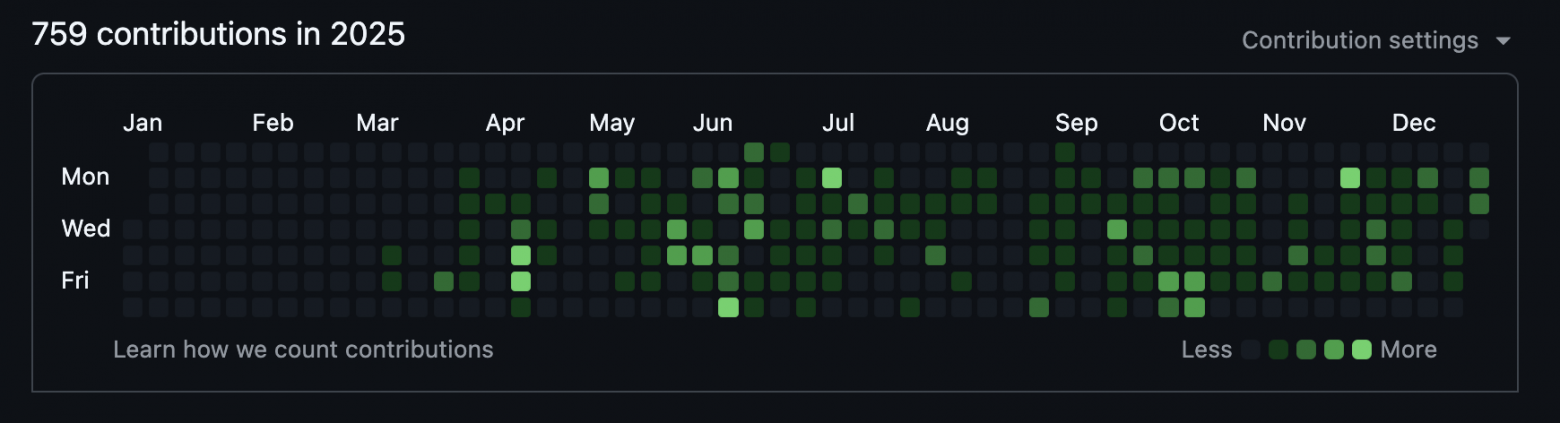
Для сравнения статистика моего GitHub за 2024 год (да и любой другой год до этого) выглядит так:
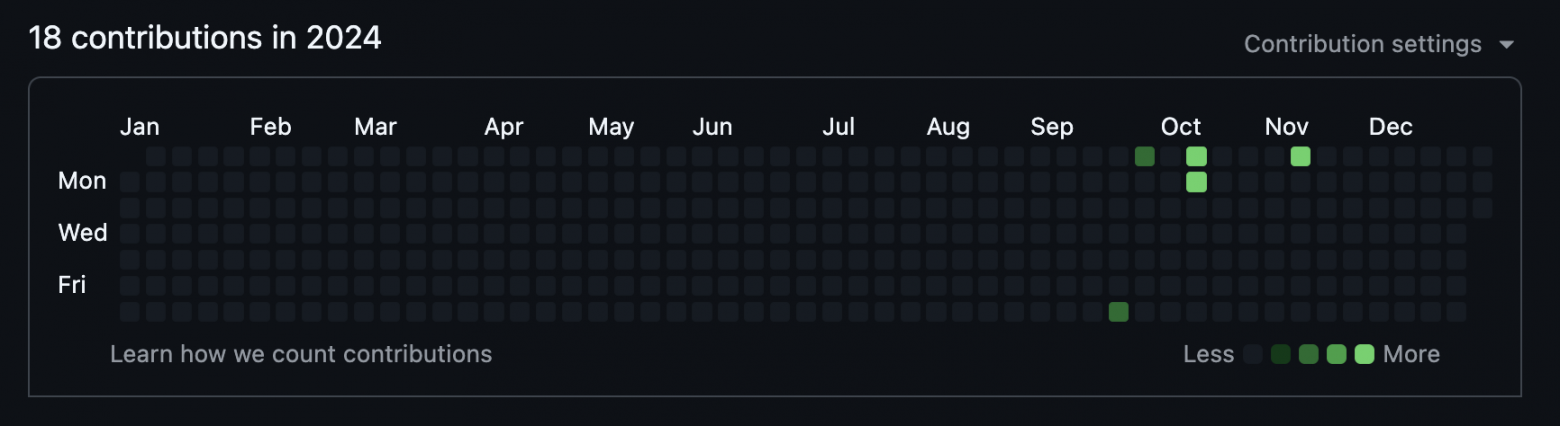
Исключительная разница.
И мне очень хочется показать этот сдвиг/переход/квантовый скачок, который у меня произошел. Возможно, кого-то вдохновить — особенно тех, кто узнает себя в моём описании. Технические руководители, которые скучают по коду. Аналитики, которые хотят делать прототипы своими руками. Бэкендеры, которых пугает фронтенд.
И поделиться своими практиками, инструментами и некоторыми рекомендациями, который выработались за почти год использования кодовых агентов. Что-то точно будет вам знакомым, что-то, возможно, предостережет от граблей, на которые я уже наступил, а что-то захочется попробовать самостоятельно.
От Full Stack к Full Cycle Engineer: небольшое лирическое отступление
Мне всегда нравился термин "fullstack". И вообще нравилось быть fullstack-разработчиком. Раньше это просто означало сделать задачу целиком, то есть от начала и до конца.
2005-2009. Я начал программировать коммерческие проекты ещё в институте. Тогда это был LAMP-стек: PHP и всё что связано — HTML, CSS, JavaScript. Я застал момент, когда только появился AJAX и мой одногруппник с горящими глазами рассказывал о том что можно обновить лишь небольшую часть страницы без перезагрузки всей страницы целиком. Это на тот момент была просто магия. Существовало даже такое понятие — "динамический JavaScript". Времена были простые.
2009. Начал работать над более серьёзными проектами - крупными информационными системами. Моя роль называлась Fullstack разработчик. Backend на Java, frontend на JavaScript. И мы в маленькой команде из 3 человек делали абсолютно всё: собирали требования, выбирали стек, проектировали архитектуру, писали спецификации, проектировали базы данных, писали SQL, серверный код, фронтенд, деплоили.
2010-е. Времена менялись. Количество технологий росло. Docker, Kubernetes, микросервисы, облака. В 2018 году Netflix написали свою знаменитую статью и ввели термин Full Cycle Developer (на самом деле Team) — команда с множеством необходимых ролей, чтобы взять полную ответственность за часть продукта от требований до исправления багов на продакшене.
После этого специализация только усиливалась. Frontend-разработчики, backend-разработчики на конкретном языке, JavaScript-разработчики на конкретном фреймворке, DevOps-специалисты. Понятие T-shaped специалиста, конечно, существовало, но в целом — специализация росла пропорционально количеству новых технологий.
Я профессионально развивался вместе с индустрией. Из разработчика стал ведущим, потом тимлидом, руководителем команды, руководителем нескольких команд. Но понятие fullstack-разработчика для меня и нашей команды всегда оставалось ключевым. Мы старались нанимать людей, которые могут, на сколько это конечно возможно, закрывать задачу целиком.
Но в какой-то момент с ростом технологий — их количества, сложности, многообразия — мы вынужденно скатились в специализацию. Стали нанимать отдельных узкоспециализированных специалистов и под новые роли адаптировать все процессы.
2025. И что же мы видим теперь?
Весь этот год я был, если отсылаться к Netflix, Full Cycle — но только один. Один инженер, который делает абсолютно всё. Full Cycle Engineer.
Кстати, спустя 20 лет в одном из проектов я вернулся к PHP, с которого начинал. Но об этом чуть позже.
Мой 2025 год в качестве Full Cycle Engineer
Если крупно перечислять чем я занимался:
-
Программировал на JavaScript, TypeScript, PHP, Python (до этого писал преимущественно на Java и 10 лет назад).
-
Настраивал инфраструктуру — bash, Terraform, Ansible, GitHub Actions (до этого ни разу не делал самостоятельно ничего из области Devops).
-
Писал скрипты автоматизации на bash и Python.
-
Сделал множество презентаций "как код"
Всё это благодаря инструментам, которые стали доступны.
В команде я, как правило, выполняю задачи, связанные с интеграцией в широком смысле этого слова. Сюда входит всё: от инфраструктуры до объединения бэкенда с фронтендом и разработки самого фронтенда, подготовки материалов для сдачи работ заказчикам и много чего еще.
Было достаточно задач, которыми я до этого никогда не занимался или занимался редко. Часть результатов меня особенно впечатлили, а где-то я набил множество шишек. Ниже расскажу про три не самых типичных в моем случае, но всё же интересных проекта.
Проект первый: PHP, формы и "я всё сделал за час"
Это был один из первых коммерческих проектов, которые я сделал в Cursor.
Задача: Нам нужно было сделать сервис для редакторов новостных изданий с использованием AI. Поиск новостей, анализ, генерация постов, картинок. Вся генеративная часть была написана на Python, упакована в API. И к этому API нужен был нормальный интерфейс — для тестирования, для сдачи работ, для отладки, для возможной интеграции в систему заказчика.
Плюс заказчик настоял, что интеграционный модуль в его систему должен быть написан на PHP. Ну, мы согласились. Почему бы нет.
Проблема: После реализации AI части, встал вопрос: что делать с PHP и веб-формами? В нашей команде не было ни фронтендеров, ни, конечно же, PHP-разработчиков.
Похоже настал черёд попробовать Cursor по-настоящему.
Что сделал: Взял задокументированный API, требования ТЗ, и написал один промпт. Монстр-комбо-мега-промпт. Примерно так: "У нас есть вот такая задача, нам надо сделать веб интерфейс, нам надо сделать PHP модуль интеграции, интегрировать с API, чтобы можно было тестировать и сдавать работу заказчику. Упакуй все в docker и напиши необходимую отчетную документацию". One-shot, буквально.
Я уже даже забыл к тому моменту, что существует такое понятие как веб-сервер Apache. Что там всякие rewrite urls. Как вообще на PHP что-то делается.
Включил режим агента без подтверждений и погнали. Спустя примерно 30 минут агент отчитался что все выполнил и даже протестировал.
Результат: Шок. Просто шок.
На выходе: готовый полноценный проект, аккуратно упакован в Docker. Все запускается, интерфейс удобный, документация присутствует. И самое главное - все реально работает.
Сказать что я был под впечатлением, это ничего не сказать. Я сообщил команде о том что задача готова буквально в стиле "А как тебе такое, Илон Маск?" - я сделал все меньше чем за час (хотя закладывал на это больше недели и как потом покажет практика - не зря). И еще какое-то время всем вокруг показывал и рассказывал про Cursor и полученные результаты.
А потом началось самое интересное.
Мы всё показали заказчику. Заказчик отметил что выглядит приятно и удобно пользоваться. Супер. Как всегда попросил сделать несколько правок и доработок.
И вот тут началась боль. Та самая, которую слышишь от большинства людей, которые впервые пробуют решать задачи с помощью AI-агентов.
Всё начало сыпаться. Каждое изменение портило предыдущий результат. Даже самые незначительные правки добавляли множество новых ошибок. А добиться какой-то точечной корректировки интерфейса - это было настоящим кошмаром.
Еще неделя и финальный результат был готов. В этот момент начало приходить понимание что не все так легко дается и придется выстраивать процесс работы с агентом.
Выводы из этого проекта будут в разделе про практики. Спойлер: one-shot для такого объема задач не работает (как собственно и в классической разработке без использования кодовых агентов).
Проект второй: лендинг за 4 часа
Мы собирали грабли, набивали шишки. Нашли подходы и практики, которые надежно работают. Решили, что пора этими знаниями поделиться — так появилась образовательная программа, которую мы хотели представить на сайте.
Сайта не существовало. Как и фронтенд-разработчика в команде.
Я никогда не работал с современным фронтендом. Последнее мое воспоминание — что стек очень сложный и быстро меняется. Миллион технологий. Frontend-разработчики теперь отдельная полноценная роль с внушительным набором компетенций. Свои пакетные менеджеры, зависимости, фреймворки, библиотеки, CSS-препроцессоры. Множество мемов про то, что такое frontend в 2024 году. В общем, было страшно.
Я помню, как во времена, когда руководил разработкой — мы делали лендинг нашей команды. Это был полноценный проект. Проектная команда, все роли: аналитик, руководитель проекта, дизайнер, фронтенд-разработчик, DevOps-инженер. Это всё длилось несколько месяцев. Agile, митинги, итерации.
А теперь все это предстоит сделать мне. Одному. Но как говорится, глаза боятся, а руки с помощью Cursor делают.
Что получилось: Сел и за четыре часа сделал первую версию лендинга. С деплоем.
Выбрал стек. Всё собрал. Написал все тексты. Разобрался и применил какие-то маркетинговые фреймворки для лучшей подачи информации. Помимо того что все работало, оно еще и красиво выглядело (на мой взгляд конечно же).
Ощущение: Опять вау-эффект. Удовлетворение.
Новая роль и новый навык разблокированы. Я почувствовал силу и способность делать фронтенд на любых проектах.
Я так впечатлился, что даже скинул результат senior frontend-разработчику с которым ранее вместе работал. Он хорошо оценил проделанную работу.
Проект третий: DevOps шаблон для повторяемой инфраструктуры
Дальше была череда похожих проектов по разработке AI-агентов, которые предстояло сдавать заказчику на его ресурсах. Разворачивать сервера, настраивать, создавать контур разработки, создавать промышленный контур заказчику, создавать CI/CD пайплайны.
Пришла пора погружаться в область DevOps. Как вы можете догадаться, DevOps-инженера в нашей команде не было.
Про мой опыт с DevOps: У меня были хорошие представления о DevOps инструментах и практиках на высоком уровне, разумеется только теоретические. Когда руководил разработкой — мы настраивали CI/CD пайплайны, распиливали монолиты, переходили сначала на Kubernetes, а потом мигрировали в облака. Я знал технологический стек. Но никогда ничего руками сам не делал. Во всех прошлых проектах использовал Jenkins или Gitlab CI, selfhosted-версии.
Для небольшой команды такой вариант избыточен, поэтому мы пользуемся GitHub, у которого есть свои GitHub Actions. На тот момент я про него лишь слышал краем уха.
История из прошлого опыта:
Когда я руководил разработкой, проект активно рос. Мы применяли микросервисную архитектуру и количество сервисов достигало нескольких сотен.
В этот период остро встал вопрос шаблонизации. Каждому сервису нужны базовые вещи: CICD пайплайны, конфигурации, стартеры. Много всего, что повторяется. Когда создаёшь новый сервис — предстоит выполнить ряд рутинных операций: создать конфиг, применить настройки, добавить параметры и т.д.
Решалось это документацией: "сделай раз-два-три, пройди все шаги". Но с ростом количества специалистов и сервисов мы несколько раз серьёзно задумывались о том, чтобы сделать SDK. Консольный инструмент, который создаёт все необходимые вещи автоматически. Тогда нужно было бы поддерживать только шаблон для этого SDK.
До реализации не дошло. Всегда было что-то важнее. Даже такой масштабный проект развивался на основе документации.
С инфраструктурой аналогичная история. Сначала одно окружение, потом другое, потом облако. Таже проблематика в ещё большем масштабе.
И вот теперь — решение:
Уже наученный опытом, понимая как работают примеры для агентов (об этом будет в разделе про практики), я решил сделать шаблонизированный репозиторий, rоторый потом можно с помощью агента адаптировать под конкретный проект в простом диалоговом режиме.
Этот шаблон включал:
-
Terraform-конфигурацию для настройки облачного сервера
-
Ansible-роли для базовой настройки (утилиты, безопасность, маршрутизация, прокси, доступы)
-
Ansible-роли для развёртывания (эти как раз приходилось немного адаптировать под каждый проект)
-
GitHub Actions pipeline: сборка, публикация образов, развёртывание на сервер
Сделал из этого шаблон репозитория и потом многократно применил.
Применение очень простое: "Вот возьми репозиторий с шаблоном, вот мой текущий проект, он так-то описан — адаптируй инфраструктуру под него". Адаптация заключалась в переписывании docker-compose, выборе параметров конфигурации, редко установки дополнительных зависимостей. Всё остальное — из базового шаблона.
Почему это важно:
С агентами делать такие вещи становится легко. Ты делаешь шаблон, говоришь "вот тебе референс" — и не надо думать, какую логику закладывать, чтобы этот референс применить. Не надо писать SDK. Не надо поддерживать кодовую базу инструмента.
Этот подход можно применять всем. Даже если вы не разрабатываете с агентами постоянно — конкретно эту задачу можно решить таким образом.
Результат: Ещё одна область и навык разблокирован на пути к Full Cycle Engineer.
Что дальше
Эти три примера небольшая часть того, что мне приходилось делать за год. Возможно это не самые типовые проекты, но они хорошо показывают, что значит быть Full Cycle Engineer, когда весь жизненный цикл создания ПО закрывает один специалист.
И было еще много других проектов и совершенно новых для меня задач, которые позволили многому научиться и выработать рабочий процесс с использованием кодовых агентов, который мне кажется эффективным. Рядом практик в виде небольших советов я поделюсь ниже.
Markdown и Mermaid — база
Это даже не отдельный совет, скорее инструментальная основа для всего нижеперечисленного.
Markdown — база для любой документации. Планы, спецификации, принятые решения, посты, статьи, письма и даже презентации — всё в Markdown. Агенты отлично его понимают, легко редактировать, версионируется в Git. Очень удобно потом трансформировать в другие форматы или импортировать в другие инструменты (Google Docs или Notion)
Mermaid — для диаграмм. Вместо того чтобы описывать сложные концепции словами, рисуешь диаграмму кодом. Агент генерирует Mermaid, Cursor его рендерит, сразу видишь результат. Аналогичная простота трансформации и импорта в другие инструменты. Ну и конечно же они прекрасно отображаются и в чате с агентом в Cursor и в ваших любимых IDE и на github или gitlab.
Помимо очевидных диаграмм, например диаграммы последовательности или компонент, есть еще ряд дополнительных, которые могут быть полезны не только для разработчиков и архитекторов.
Например:
-
User Journey
-
Gantt и Kanban
-
Quadrant Chart, Radar, Treemap
-
GitGraph (Git) Diagram
-
Mindmaps и Timeline
Это прямо must-have.
Декомпозиция и планирование
Помните мой первый проект с PHP? Монстр-комбо-промпт, one-shot, "сделай всё" — и через час готовый результат. А потом каждое изменение ломало предыдущее.
Вот это и есть главный урок, на основе которого выстроился надёжный и контролируемый процесс. Он характерен для классической разработки — декомпозиция, трассировка, планирование, задачи, итерации, описания.
Структура проектной документации:
К каждому проекту создаётся набор описательных документов. Для небольшого проекта это может быть один документ, который включает всё: видение, технический стек, особенности, ограничения.
Дальше набор итераций на высоком уровне (дорожная карта). Каждая итерация содержит список задач. Каждая задача содержит:
-
Цель
-
Список действий
-
Список проверок
-
Список артефактов
-
Definition of Done
Немного адаптированный список задач из реального проекта:
# Backend Integration Tasklist ## Обзор Пример структурированного task list для интеграции backend сервиса с внешним API. Включает прием токенов авторизации, обработку запросов через AI Agent и интеграцию с внешними сервисами. ## Принципы - **Contract-first**: API реализуется согласно документированным контрактам - **Incremental delivery**: Поэтапная реализация с возможностью тестирования на каждом шаге - **Token security**: Безопасная передача токенов через все слои системы ## Легенда статусов - 📋 Planned - Запланирован - 🚧 In Progress - В работе - ✅ Done - Завершен ## План итераций | Итерация | Описание | Статус | |----------|----------|--------| | BI-1 | Прием токена и конфигурация внешнего сервиса | ✅ Done | | BI-2 | Agent API с Human-in-the-Loop | ✅ Done | | BI-3 | Интеграция Tools с внешним API | ✅ Done | --- ## BI-1: Прием токена и конфигурация ✅ ### Цель Настроить прием токена авторизации с frontend через Authorization header и конфигурацию для вызовов внешнего API. ### Описание состава работ **Конфигурация Settings** - [x] Добавить настройки для внешнего API - [x] Добавить токен для service-to-service аутентификации - [x] Настроить fallback значения для разработки **Извлечение токена из request** - [x] Реализовать парсинг Authorization header - [x] Добавить обработку формата `Bearer {token}` - [x] Добавить логирование для отладки **Прокидывание токенов в Agent** - [x] Передача токенов через конфигурацию агента - [x] Документирование структуры конфигурации **Docker Compose обновление** - [x] Добавить environment variables для токенов - [x] Обновить конфигурацию для production **Тестирование** - [x] Интеграционные тесты передачи токенов - [x] API тесты для endpoints - [x] Команды для запуска тестов ### Проверка - [x] Backend запускается с новыми переменными окружения - [x] Authorization header парсится корректно - [x] Токены доступны во всех слоях системы - [x] Docker Compose корректно передает конфигурацию - [x] Все интеграционные тесты проходят
Пример структуры документации проекта:
doc/ ├── adr/ # Architecture Decision Records ├── project/ # Проектные документы │ ├── project-plan.md # Общий план проекта │ └── requirements.md # Требования к системе │ ├── tasks/ # Детальное планирование │ ├── iterations/ # Планы и отчеты по итерациям │ │ ├── backend/ # Backend итерации │ │ ├── backend-integration/ # Интеграционные итерации │ │ ├── devops/ # DevOps итерации │ │ └── frontend/ # Frontend итерации │ ├── tasklist-backend-integration.md # Общий tasklist интеграции │ ├── tasklist-backend.md # Backend tasklist │ ├── tasklist-frontend.md # Frontend tasklist │ └── tasklist-template.md # Шаблон для новых tasklist │ ├── tech/ # Техническая документация │ ├── architecture/ # Архитектурные диаграммы │ └── specs/ # Спецификации фич │ └── workflow.md # Описание рабочего процесса
Мой рабочий процесс:
В описании задачи я формулирую тезисные требования на высоком уровне — то, что мне понятно.
Дальше планирую работу с использованием Plan Mode в Cursor. Это режим, когда агент не пишет код, а:
-
Анализирует задачу
-
Собирает необходимый контекст
-
Задаёт уточняющие вопросы
-
Предлагает варианты реализации на согласование
После всех уточнений получается настоящий план реализации — документ со всеми подробностями. Там уже могут быть примеры кода, перечень файлов, низкоуровневые технические детали.
И только потом — реализация по этому плану.
Почему это важно:
Агент работает в рамках одной итерации. Закончили — проверили — зафиксировали — перешли к следующей.
Звучит очевидно? Да. Но когда перед тобой инструмент, который за час может нагенерить целый проект — очень хочется сказать "сделай всё". И потом две недели разгребать.
Spec-driven подход
Уже довольно устоявшийся термин. Есть даже несколько специализированных IDE (Kiro, Qoder) и Spec Kit от Github.
Spec-driven — это когда ты детально описываешь что нужно сделать, до того как агент начинает писать код.
Не "сделай форму авторизации", а:
-
Какие поля
-
Какая валидация
-
Что происходит при ошибке
-
Куда редиректит после успеха
-
Как выглядит (можно скриншот)
-
Какие API-эндпоинты использует
-
Как обрабатывать edge cases
Чем детальнее спецификация — тем предсказуемее результат.
Как это выглядит на практике:
Я уже упоминал про Plan Mode в Cursor. Это режим, когда агент не пишет код, а только составляет план. Обсуждаем, уточняем, фиксируем. И только потом — реализация.
Сам план обязательно сохраняю в Markdown-файл и делаю ссылку на него в спеске задач.
Валидация крайне важна. После того как агент задал все уточняющие вопросы и составил план, я внимательно досконально его проверяю и корректирую. Иногда отдельные предложения могу покритиковать другим агентом или моделью (какие есть риски, альтернативы, возможные проблемы, более простое или элегантное решение или наоборот более гибкое и сложное).
Итог: Когда понятно, что надо делать — результат получается чёткий. Меньше переделок, меньше сюрпризов.
Примеры/референсы
Это один из самых полезных приёмов, который я освоил за этот год.
Референс или пример - это набор данных, на основе которого агент делает работу. И понятие примера здесь многогранное.
1. Визуальные примеры — скриншоты, дизайн
Если делаешь фронтенд — можно показать скриншот желаемого интерфейса и попросить агента привести в соответствие. Визуальные модели очень хорошо понимают картинки. Модели Anthropic, по моему личному мнению, особенно хороши в этом.
2. Документация — quick start, мануалы
Обязательно для применения в проектах на современных фреймворках и библиотеках, про которым LLM ничего не знают. Вообще кажется довольно очевидным, но слишком много людей жалуются на выдумки моделей.
Ссылаешься на документацию. "Вот quick start, вот примеры кода — адаптируй для моего проекта".
Агент читает документацию и адаптирует под твою структуру. Это работает сильно лучше, чем пытаться объяснить своими словами то, что уже хорошо описано в официальных доках.
3. Репозитории — исходный код
Можно дать агенту целый репозиторий как референс. "Хочу такую же структуру, такую же архитектуру". Агент анализирует и переносит паттерны в твой проект.
Именно так я делал CI/CD шаблон — сначала создал референсный проект, потом многократно адаптировал.
Также часто применял для инициализации новых проектов с интерфейсом на React или Next.js.
4. Тетрадки (Jupyter notebook)
Jupyter notebook очень удобно использовать для исследования новых областей и для создания Proof of concept.
Мы делаем много таких задач при разработке ИИ-агентов. Сначала исследуем: пробуем, экспериментируем, проверяем гипотезы. Всё это оформляем в виде "тетрадки" — Jupyter notebook или просто Markdown-документ.
Тетрадка — это одновременно:
-
Proof of concept — проверка что вообще можно сделать
-
Документация для себя и команды
-
Референс для агента
Потом, когда переходишь к разработке и у тебя уже есть структура проекта, говоришь: "По этому референсу имплементируй такую-то возможность, интегрируй в мою архитектуру".
Референсы очень здорово работают. Это прямо must-have в арсенале.
Контроль
Агент пишет много и быстро. Это и благословение, и проклятие.
Проблема касается всего, что генерирует агент: скрипты, код, документация. Но если код и скрипты мы хотя бы худо-бедно просматриваем, запускаем, тестируем — вручную или автоматизированно — то документацию читаем по диагонали.
И вот это не так очевидно, но документация — причина большого количества неожиданностей и проблем в будущем.
Документация иногда опаснее кода
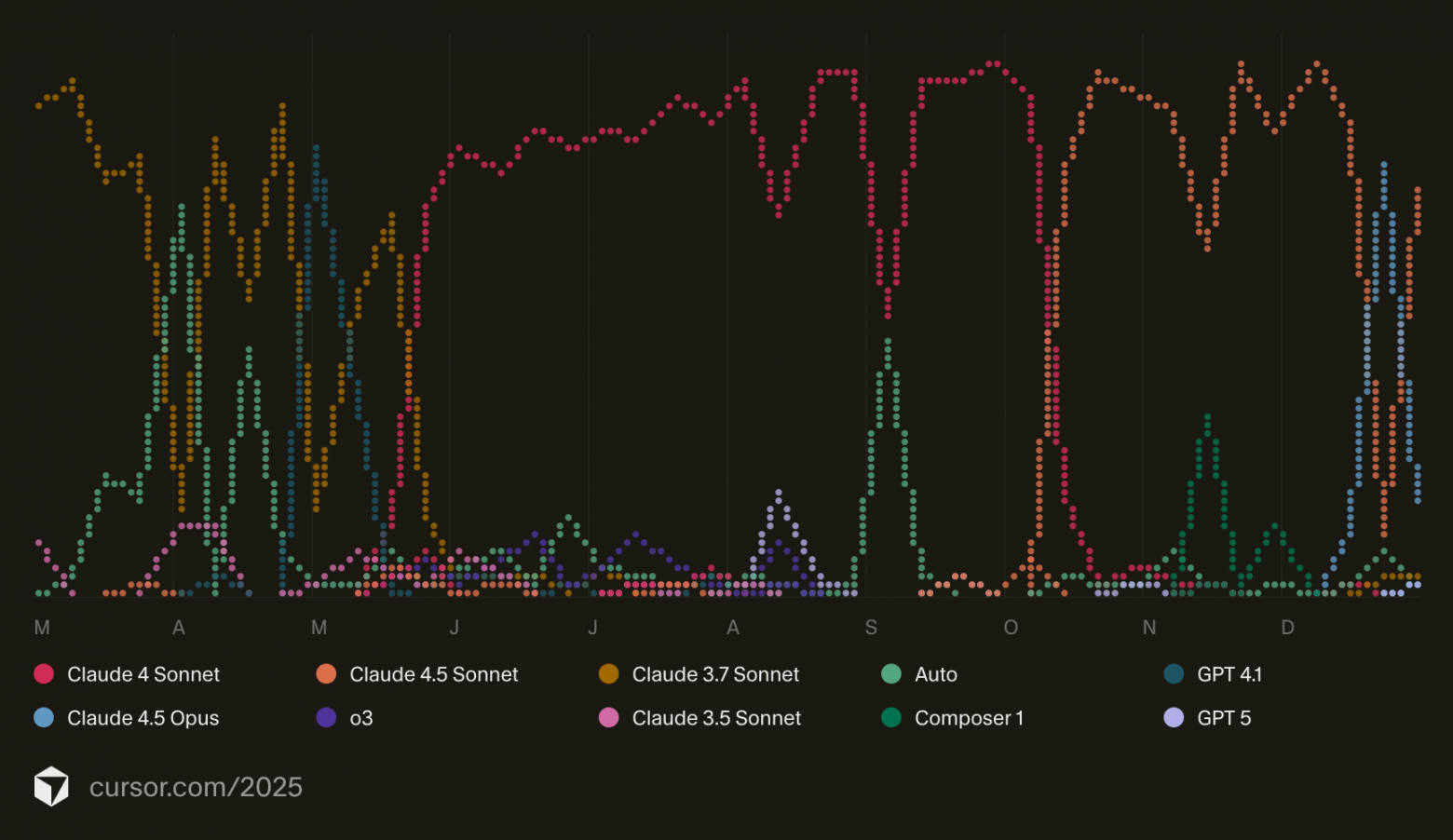
Я пользовался разными моделями, но чаще всего Sonnet и иногда Opus
Модели Anthropic слишком креативные и инициативные. Модели других провайдеров надо прямо уговаривать самостоятельно что-то исправить, вместо того чтобы описывать что надо сделать пользователю. Sonnet и Opus наоборот, просто на любой чих генерируют README, инструкции, описания ошибок и исправлений, наблюдения и сравнения о которых даже не просишь.
Если вы эту документацию не смотрите — она потом запросто может выстрелить в ногу. Неожиданно окажетесь в неудобной ситуации: покажете что-то из документации заказчику, или будете развивать проект, и эта документация станет источником знаний для агента. А там — неточности, устаревшая информация, лишние детали.
В следующей итерации агент прочитал этот документ (потому что он в контексте проекта). И на основе не совсем точной или избыточной информации принял решение. И вот у тебя уже испортился код.
Решение — правила:
На уровне системных правил проекта (или даже глобальных правил пользователя) я фиксирую:
-
Документы создаются только после согласования со мной
-
У каждого документа должна быть понятная цель
-
Содержимое — ёмкое, лаконичное, минимально необходимое и достаточное
-
Для визуализации — диаграммы (Mermaid), не простыни текста
-
Минимум примеров кода в документации
-
Никакой лирики и воды
Это реально помогает. Агент перестаёт генерировать тонны ненужных файлов. Ну и конечно тратить на это драгоценные токены.
Контроль в целом:
Это не только про документацию. Это про всё, что делает агент.
Проверять результат. Не доверять слепо. Понимать, что агент сделал и почему. Это база, но про неё легко забыть, когда результат появляется быстро и выглядит красиво.
Документирование
Парадокс: когда я руководил разработкой — формировать документацию было настоящим мучением, ведь разработчикам куда интереснее писать код. Но чем больше команда, тем важнее качественная актуальная документация. Все знают, что документация устаревает, что это боль, но без неё никак.
С агентами — обратная сторона. Документировать стало легко. Слишком легко. И теперь нужно контролировать, чтобы документации не было слишком много (см. предыдущий раздел).
Но при этом есть вещи, которые документировать обязательно.
1. Планы выполнения задач
Перед началом работы — план в Markdown. Что делаем, какие задачи, какие критерии готовности, какие задачи связаны между собой.
Как уже писал ранее - использую режим Plan Mode в Cursor, сохраняю результат в виде Markdown-файла и делаю ссылку в списке задач.
2. Результаты и итоги выполнения задачи (Post-implementation summary)
После завершения задачи — краткое или возможно более развернутое резюме. Что сделано, какие решения приняты, какие проблемы возникли и как решили.
Это очень важно. Помогает и агенту потом понять, что было сделано и почему, и мне вспомнить контекст.
3. ADR — Architecture(Any) Decision Records
Фиксация принятых решений. Куда деплоим, чем собираем, какую базу выбрали, какую ORM используем, почему используем или не используем асинхронные операции, как управляем зависимостями.
Я использую ADR почти на всех проектах, даже если делаю один. Почему? Потому что очень много новых инструментов, библиотек, технологий. Как правило у меня недостаточно или совсем нет промышленного опыта в новой области/стеке, чтобы принимать решения самостоятельно. Поэтому каждое решение проходит через этап исследования, результат которого документируется в ADR.
Сам процесс исследования и принятия решения часто включает использование ChatGPT/Claude/Perplexity с функциями Deep Research и последующее обсуждение результатов с кодовым агентом.
Дополнительный плюс документирования для пользователей Cursor
Конечно вся история работы есть в чатах Cursor. И все уже слышали рекомендацию для каждой новой задачи создавать новый чат.
Есть даже функции саммаризации чатов, экспорта и ссылок.
Но лично я несколько раз терял всю историю чатов при обновлении Cursor. Без возможности восстановления.
Если бы не было отдельной документации — было бы очень тяжело вспомнить, что и как делали. Так что документация — это ещё и страховка.
Cursor как база знаний
Cursor — это не только IDE для программирования. Его можно легко использовать как универсальную базу знаний и инструмент для работы с любым текстом.
Абсолютно все текстовые и производные материалы я делаю в нём:
-
Посты для канала и статьи
-
Сценарии для видео
-
Коммерческие предложения
-
Техническое задание
-
Отчётная документация
-
Заметки и многое другое
Почему это работает? Потому что подход один и тот же. Даёшь контекст, даёшь референс, итеративно доводишь до результата. Неважно, код это или текст КП.
Около половины моих коммитов в GitHub это не код, а именно текст.
Главное - это самая простая возможность начать использовать кодовых агентов для специалистов других областей, которые далеки не только от кода, но и от ИТ в целом.
Презентации в Markdown
Это моя отдельная боль, которая наконец-то решилась.
Презентации нужны всем. Я лично делал их и раньше — для выступлений, для отчётов, для сдачи работ заказчикам и подведения итогов. И всегда это была боль. PowerPoint, слайды, выравнивание, шрифты, "почему этот блок съехал".
Я тихо завидовал ребятам, которые на Хабр восторженно рассказывали, как они готовят всё в Markdown или AsciiDoc и потом экспортируют в классные презентации.
Но тогда такой синтаксис был ещё большим стопором. Надо выучить, надо помнить, надо руками писать. Кстати я также считал что с помощью Markdown разметки невозможно сделать сложную верстку слайда. Разумеется ошибался.
В общем я так и не осилил, хотя и понимал, что это намного проще и удобнее. Пока не стал использовать Cursor.
А теперь не только готовлю, но и демонстрирую их прямо в Cursor.
Небольшой тулсет:
-
Reveal.js Markdown — синтаксис для Reveal.js
-
vscode-reveal — плагин для Cursor, который рендерит прямо в редакторе (включая mermaid диаграммы)
Сама подготовка не отличается от всего остального:
-
Выгружаю материалы и мысли
-
Даю референс на полный синтаксис Reveal.js
-
Даю пример хорошей презентации, если есть
-
Пара правил — какие хочу заголовки, какой стиль, как оформлять код и диаграммы, использовать ли emoji
-
Готово
Плюсом все возможности экспорта в другие форматы, в частности в PDF.
Инструменты
Cursor — это мой главный инструмент. В нем огромное количество возможностей, которые я использую каждый день и каждую новую функцию сразу беру на вооружение. Плагины использую минимально.
SuperWhisper — голосовой ввод. Вообще голосовой ввод использую во всех своих инструментах на всех платформах. Есть аналоги под все ОС и более качественные, но я привык к данному инструменту.
ChatGPT и Claude — для всего и особенно для deep research. Даже незначительные вопросы прогоняю через глубокий анализ.
Warp Terminal — раньше просто удобная консоль, но сейчас уже позиционируется как кодовый агент. Чаще всего использую для задач автоматизации и установки инструментов.
Perplexity — для быстрого поиска или исследования.
Вместо заключения
Пока я писал эту статью, произошло кое-что показательное.
26 декабря 2025 года Андрей Карпатый — сооснователь OpenAI, экс-директор AI в Tesla, автор термина "vibe coding" — написал в Twitter:
На следующий день ответил Борис Черный — создатель Claude Code, Principal Engineer:
Создатель одного из самых успешных AI-инструментов в истории — перестал открывать IDE и писал код самостоятельно.
Оба твита набрали 20 миллионов просмотров и активно обсуждались в сообществах.
И вот что еще интересно:
Новички эффективнее ветеранов. Потому что у них нет "legacy memories" — устаревших представлений о том, что AI может и не может.
Я вижу это постоянно, включая себя. Каждый раз, когда думаю "это точно не сработает" — оказывается, что сработает. Модели меняются быстрее, чем наши представления о них.
Вся индустрия меняется стремительно. Меняются инструменты, модели, подходы. Но самое главное — меняются роли.
Системный аналитик в нашей команде самостоятельно развивает проект, который раньше делала целая команда. Junior-специалист закрывает проекты в одиночку (это просто переворачивает весь мой прошлый опыт работы, когда найм Junior специалиста был большим риском и настоящей инвестицией). Продакт-менеджер идёт от гипотезы до работающего прототипа без привлечения разработчиков. Таких примеров уже достаточно много.
Человек с идеей и горящими глазами теперь может запустить свой стартап. Или хотя бы реализовать давнюю идею, которая годами лежала в заметках.
Надеюсь, мой опыт кого-то вдохновит попробовать. Если какие-то практики или подходы показались интересными — задавайте вопросы, обсудим.
Спасибо, что дочитали до конца!
Про AI-инструменты, практики и свой опыт AI-driven разработки регулярно пишу в Telegram: @aidialogs
Источник
Вам также может быть интересно

Дженсен Хуанг предупреждает о квантовых рисках в цифровой безопасности

Сооснователь DWF Labs: Завершил инвестиции в размере 1 миллион $ в DeFi-проект на посевном раунде
