

Устойчивое маскированное матирование: управление зашумленными входными данными и универсальностью объектов
Таблица ссылок
Резюме и 1. Введение
-
Связанные работы
-
MaGGIe
3.1. Эффективное маскированное управляемое извлечение экземпляров
3.2. Временная согласованность функций и матов
-
Наборы данных для извлечения экземпляров
4.1. Извлечение экземпляров изображений и 4.2. Извлечение экземпляров видео
-
Эксперименты
5.1. Предварительное обучение на данных изображений
5.2. Обучение на видеоданных
-
Обсуждение и ссылки
\ Дополнительные материалы
-
Детали архитектуры
-
Извлечение изображений
8.1. Генерация и подготовка набора данных
8.2. Детали обучения
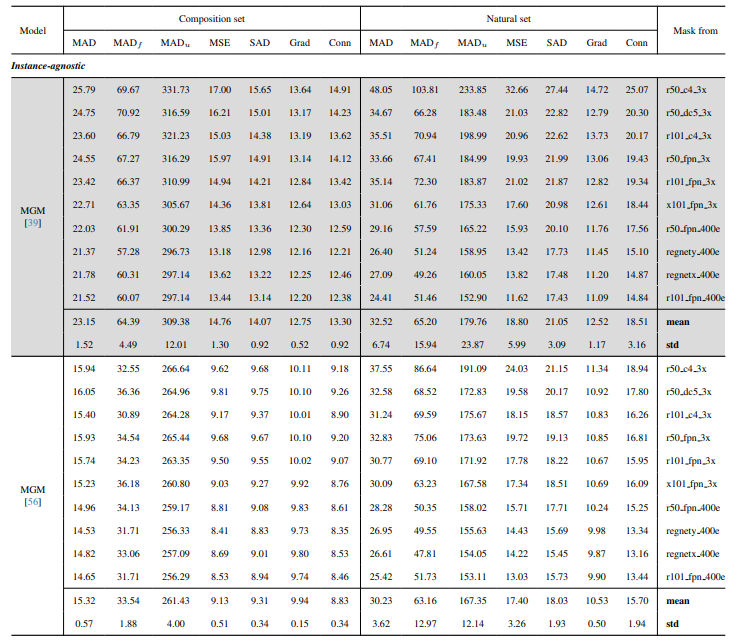
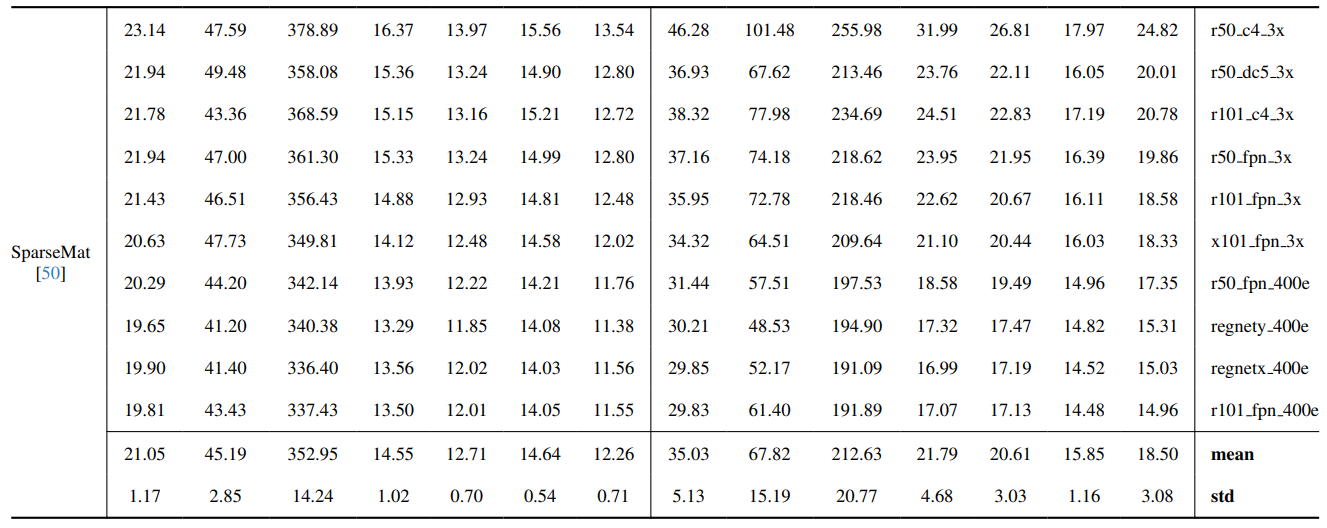
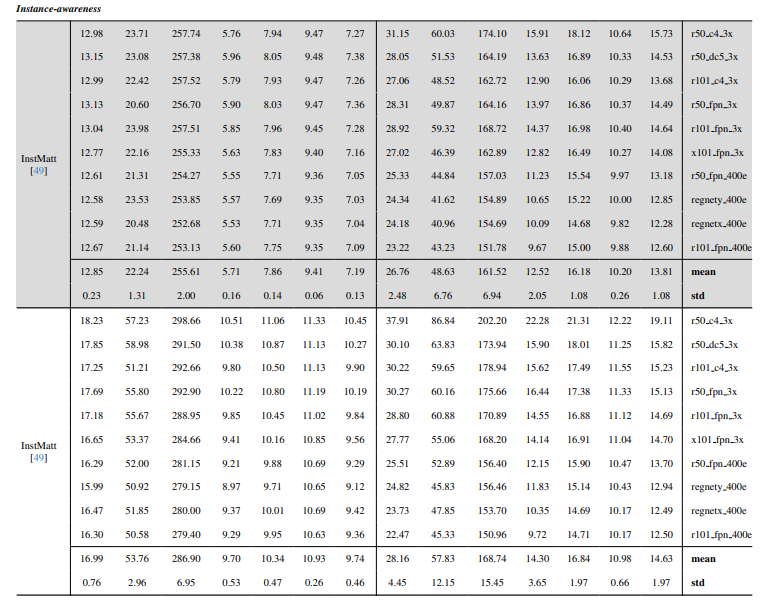
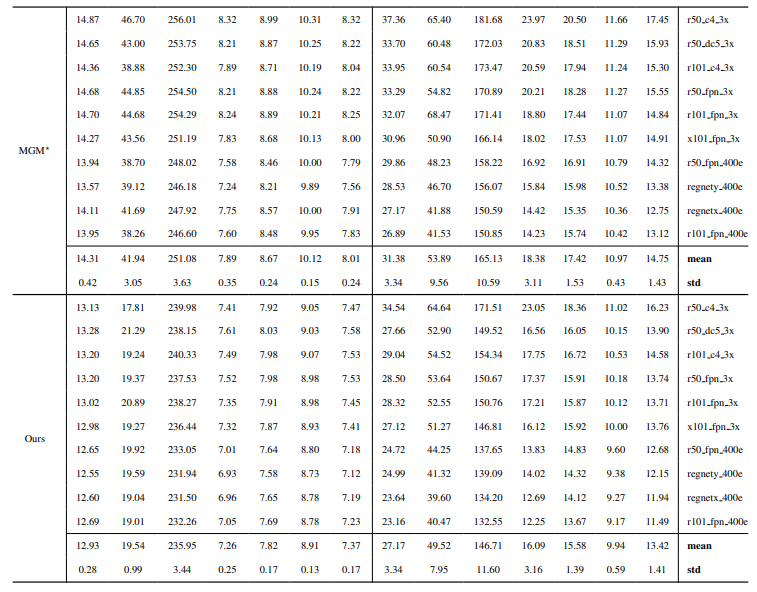
8.3. Количественные детали
8.4. Больше качественных результатов на естественных изображениях
-
Извлечение видео
9.1. Генерация набора данных
9.2. Детали обучения
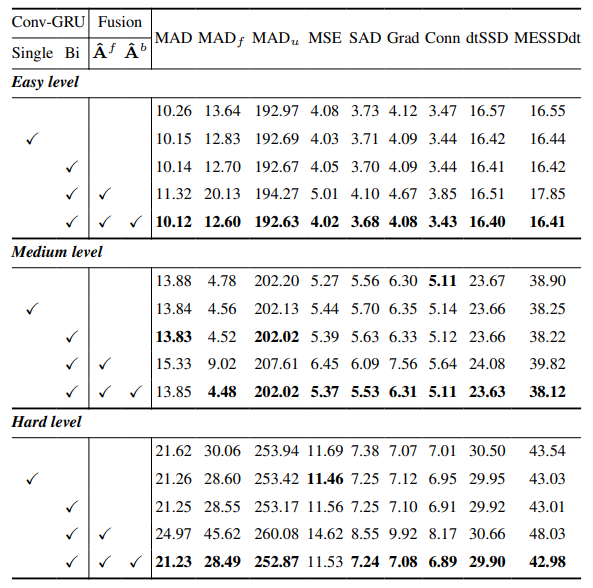
9.3. Количественные детали
9.4. Больше качественных результатов
8.4. Больше качественных результатов на естественных изображениях
Рис. 13 демонстрирует производительность нашей модели в сложных сценариях, особенно в точной визуализации областей волос. Наш фреймворк постоянно превосходит MGM⋆ в сохранении деталей, особенно при сложных взаимодействиях экземпляров. По сравнению с InstMatt наша модель демонстрирует превосходное разделение экземпляров и точность деталей в неоднозначных областях.
\ Рис. 14 и рис. 15 иллюстрируют производительность нашей модели и предыдущих работ в экстремальных случаях с множественными экземплярами. В то время как MGM⋆ испытывает трудности с шумом и точностью в плотных сценариях с экземплярами, наша модель сохраняет высокую точность. InstMatt без дополнительных обучающих данных показывает ограничения в этих сложных условиях.
\ Надежность нашего подхода с масочным управлением дополнительно продемонстрирована на рис. 16. Здесь мы выделяем проблемы, с которыми сталкиваются варианты MGM и SparseMat при прогнозировании отсутствующих частей в масочных входных данных, которые решает наша модель. Однако важно отметить, что наша модель не предназначена для работы в качестве сети сегментации человеческих экземпляров. Как показано на рис. 17, наш фреймворк следует входному руководству, обеспечивая точное прогнозирование альфа-мата даже при наличии нескольких экземпляров в одной маске.
\ Наконец, рис. 12 и рис. 11 подчеркивают возможности обобщения нашей модели. Модель точно извлекает как человеческие объекты, так и другие объекты с фона, демонстрируя свою универсальность в различных сценариях и типах объектов.
\ Все примеры представляют собой интернет-изображения без эталонных данных, и маска из r101fpn400e используется в качестве руководства.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Авторы:
(1) Chuong Huynh, Университет Мэриленда, Колледж-Парк (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, Университет Мэриленда, Колледж-Парк (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Эта статья доступна на arxiv под лицензией CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Вам также может быть интересно

EdgeX подскакивает на 29,5%, поскольку токен инфраструктуры DePIN попадает в топ-125

Range привлекает 8,3 млн $ для систем стейблкоинов

Юристы Министерства юстиции бегут в «синие» штаты, чтобы не быть «дураком или трусом» Трампа: генпрокурор-демократ



