

Data Scarcity Solution: S-CycleGAN for CT-to-Ultrasound Translation
Table of Links
Abstract and 1 Introduction
-
Related works
-
Problem setting
-
Methodology
4.1. Decision boundary-aware distillation
4.2. Knowledge consolidation
-
Experimental results and 5.1. Experiment Setup
5.2. Comparison with SOTA methods
5.3. Ablation study
-
Conclusion and future work and References
\
Supplementary Material
- Details of the theoretical analysis on KCEMA mechanism in IIL
- Algorithm overview
- Dataset details
- Implementation details
- Visualization of dusted input images
- More experimental results
Abstract
Instance-incremental learning (IIL) focuses on learning continually with data of the same classes. Compared to class-incremental learning (CIL), the IIL is seldom explored because IIL suffers less from catastrophic forgetting (CF). However, besides retaining knowledge, in real-world deployment scenarios where the class space is always predefined, continual and cost-effective model promotion with the potential unavailability of previous data is a more essential demand. Therefore, we first define a new and more practical IIL setting as promoting the model’s performance besides resisting CF with only new observations. Two issues have to be tackled in the new IIL setting: 1) the notorious catastrophic forgetting because of no access to old data, and 2) broadening the existing decision boundary to new observations because of concept drift. To tackle these problems, our key insight is to moderately broaden the decision boundary to fail cases while retain the old boundary. Hence, we propose a novel decision boundary-aware distillation method with consolidating knowledge to teacher to ease the student learning new knowledge. We also establish the benchmarks on existing datasets Cifar-100 and ImageNet. Notably, extensive experiments demonstrate that the teacher model can be a better incremental learner than the student model, which overturns previous knowledge distillation-based methods treating student as the main role.
1. Introduction
In recent years, many excellent deep-learning-based networks are proposed for variety of tasks, such as image classification, segmentation, and detection. Although these networks perform well on the training data, they inevitably fail on some new data that is not trained in real-world application. Continually and efficiently promoting a deployed model’s performance on these new data is an essential demand. Current solution of retraining the network using all accumulated data has two drawbacks: 1) with the increasing data size, the training cost gets higher each time, for example, more GPUs hours and larger carbon footprint [20], and 2) in some cases the old data is no longer accessible because of the privacy policy or limited budget for data storage. In the case where only a little or no old data is available or utilized, retraining the deep learning model with new data always cause the performance degradation on the old data, i.e., the catastrophic forgetting (CF) problem. To address CF problem, incremental learning [4, 5, 22, 29], also known as continual learning, is proposed. Incremental learning significantly promotes the practical value of deep learning models and is attracting intense research interests.
\ 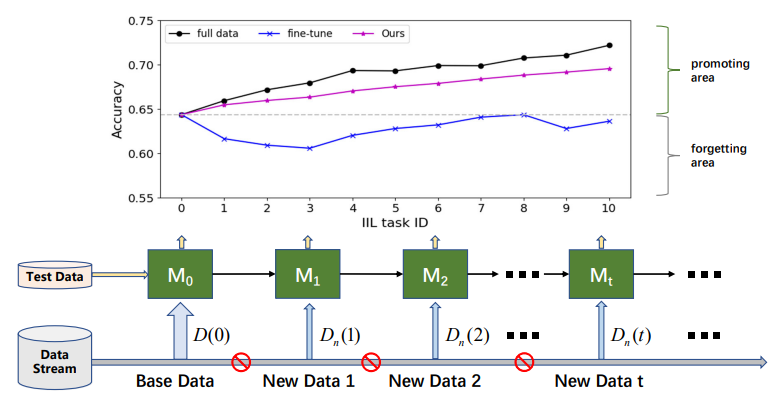
\ According to whether the new data comes from seen classes, incremental learning can be divided into three scenarios [16, 17]: instance-incremental learning (IIL) [3, 16] where all new data belongs to the seen classes, class-incremental learning (CIL) [4, 12, 15, 22] where new data has different class labels, and hybrid-incremental learning [6, 30] where new data consists of new observations from both old and new classes. Compare to CIL, IIL is relatively unexplored because it is less susceptible to the CF. Lomonaco and Maltoni [16] reported that fine-tuning a model with early stopping can well tame the CF problem in IIL. However, this conclusion not always holds when there is no access to the old training data and the new data has a much smaller size than old data, as depicted in Fig. 1. Fine-tuning often results in a shift in the decision boundary rather than expanding it to accommodate new observations. Besides retaining old knowledge, the real deployment concerns more on efficient model promotion in IIL. For instance, in the defect detection of industry products, classes of defect are always limited to known categories. But the morphology of those defects is varying time to time. Failures on those unseen defects should be corrected timely and efficiently to avoid the defective products flowing into the market. Unfortunately, existing research primarily focuses on retaining knowledge on old data rather than enriching the knowledge with new observations.
\ In this paper, to fast and cost-effective enhance a trained model with new observations of seen classes, we first define a new IIL setting as retaining the learned knowledge as well as promoting the model’s performance on new observations without access to old data. In simple words, we aim to promote the existing model by only leveraging the new data and attain a performance that is comparable to the model retrained with all accumulated data. The new IIL is challenging due to the concept drift [6] caused by the new observations, such as the color or shape variation compared to the old data. Hence, two issues have to be tackled in the new IIL setting: 1) the notorious catastrophic forgetting because of no access to old data, and 2) broadening the existing decision boundary to new observations.
\ To address above issues in the new IIL setting, we propose a novel IIL framework based on the teacher-student structure. The proposed framework consists of a decision boundary-aware distillation (DBD) process and a knowledge consolidation (KC) process. The DBD allows the student model to learn from new observations with awareness of the existing inter-class decision boundaries, which enables the model to determine where to strengthen its knowledge and where to retain it. However, the decision boundary is untraceable when there are insufficient samples located around the boundary because of no access to the old data in IIL. To overcome this, we draw inspiration from the practice of dusting the floor with flour to reveal hidden footprints. Similarly, we introduce random Gaussian noise to pollute the input space and manifest the learned decision boundary for distillation. During training the student model with boundary distillation, the updated knowledge is further consolidate back to the teacher model intermittently and repeatedly with the EMA mechanism [28]. Utilizing teacher model as the target model is a pioneering attempt and its feasibility is explained theoretically.
\ According to the new IIL setting, we reorganize the training set of some existing datasets commonly used in CIL, such as Cifar-100 [11] and ImageNet [24] to establish the benchmarks. Model is evaluated on the test data as well as the non-available base data in each incremental phase. Our main contributions can be summarized as follows: 1) We define a new IIL setting to seek for fast and cost-effective model promotion on new observations and establish the benchmarks; 2) We propose a novel decision boundary-aware distillation method to retain the learned knowledge as well as enriching it with new data; 3) We creatively consolidate the learned knowledge from student to teacher model to attain better performance and generalizability, and prove the feasibility theoretically; and 4) Extensive experiments demonstrate that the proposed method well accumulates knowledge with only new data while most of existing incremental learning methods failed.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
:::info Authors:
(1) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
\
You May Also Like

Franklin Templeton updates XRP ETF filing for imminent launch

Fed Lowers Rates By 25bps: How Bitcoin And Crypto Prices Responded And What’s Next

Canada’s budget promises laws to regulate stablecoins, following US
Canada’s government unveiled a plan to regulate stablecoins, requiring fiat-backed issuers to maintain sufficient reserves and adopt robust risk management measures. Canada is set to introduce legislation regulating fiat-backed stablecoins under its federal budget for 2025, following the footsteps of the US, which passed landmark stablecoin laws in July.Stablecoin issuers will be required to hold sufficient reserves, establish redemption policies and implement various risk management frameworks, including measures to protect personal and financial data, according to the government’s 2025 budget released on Tuesday.The Bank of Canada would allocate $10 million over two years, starting in the 2026-2027 fiscal year, to ensure everything runs smoothly, followed by an estimated $5 million in annual costs that will be offset from stablecoin issuers regulated under the Retail Payment Activities Act.Read more