

La última investigación de DGrid AI aborda un fallo fundamental en la puntuación de IA descentralizada
DGrid AI presenta un nuevo marco de Prueba de Calidad diseñado para evaluar los resultados de la IA y mejorar la distribución de recompensas en redes descentralizadas.
- La nueva investigación PoQ de DGrid AI introduce una puntuación sin referencia para recompensar los nodos de IA sin necesidad de respuestas correctas.
- DGrid entrenó jueces de IA especializados para puntuar la calidad de los resultados, mejorando los sistemas de recompensas de IA descentralizada a escala.
- Los nuevos modelos de Prueba de Calidad de DGrid AI ayudan a las redes de IA descentralizadas a evaluar las respuestas con precisión sin datos de verdad fundamental.
Las redes de IA descentralizadas tienen un problema de pagos con el que los investigadores han estado lidiando en silencio durante años, y un artículo reciente de DGrid AI pone el problema directamente sobre la mesa. Los sistemas de puntuación de calidad que impulsan las recompensas de los nodos han dependido en gran medida de tener la respuesta correcta a mano para comparar. En producción, esa respuesta rara vez existe.
El artículo, el cuarto en la serie de investigación en curso de DGrid sobre Prueba de Calidad (PoQ), propone una alternativa entrenada y publica los números que la respaldan. PoQ utiliza pequeños modelos evaluadores para puntuar la calidad de cada resultado, y esas puntuaciones impulsan las recompensas. Económico y escalable.
DGrid construyó esto ladrillo a ladrillo: una versión consciente del costo que incorpora la latencia en el cálculo de pagos, una capa de robustez adversarial que se mantiene cuando los evaluadores mienten o son perezosos, y un marco que divide la "calidad" en partes que se pueden inspeccionar. Ingeniería sólida. Y cada capa seguía chocando contra la misma pared.
Cómo se desarrolló el problema de puntuación
La estructura básica de una red de inferencia descentralizada crea un desafío de medición. Los nodos independientes ejecutan modelos de lenguaje y responden a las consultas de los usuarios. Esas respuestas deben puntuarse porque las puntuaciones determinan el pago. La verificación criptográfica de cada cálculo sería técnicamente infalible pero prohibitivamente costosa a escala, por lo que el camino práctico ha sido la evaluación automatizada de calidad utilizando modelos más pequeños.
El trabajo anterior de DGrid desarrolló ese enfoque de forma incremental, añadiendo pagos ajustados por latencia, defensas contra evaluadores manipuladores y un desglose más granular de lo que "calidad" significa realmente en un contexto de puntuación. Lo que no pudo resolver completamente fue la señal de evaluación en sí.
La señal más fuerte que tenía el equipo era la similitud semántica: comparar el resultado del modelo con una respuesta correcta conocida y medir la distancia entre ellas en el espacio de incrustación. Eso funciona en entornos de referencia donde existen respuestas de referencia. No funciona en una red en vivo donde los usuarios hacen preguntas abiertas y no hay una verdad fundamental esperando en una base de datos.
Las alternativas disponibles comercialmente dieron peores resultados. Un codificador cruzado NLI, una clase de modelo diseñada para evaluar la implicación lógica entre oraciones, devolvió una correlación de Pearson de −0,363 cuando se usó para calificar la calidad de las respuestas sin una respuesta de referencia. Una correlación negativa significa que el modelo tenía más probabilidades de favorecer las respuestas deficientes sobre las buenas. Eso no es una herramienta de evaluación utilizable.
Lo que propone el artículo
En lugar de adaptar los modelos existentes, los investigadores entrenaron tres jueces específicamente para la puntuación de calidad sin referencia. Cada uno toma una pregunta y una respuesta como entrada y genera una puntuación de 0 a 10, sin que se proporcione una respuesta correcta.
Los tres modelos difieren principalmente en tamaño y velocidad:
- TextCNN (~10M parámetros) se ejecuta en aproximadamente 1 milisegundo por llamada, lo que lo hace adecuado para el filtrado de primer paso de alto rendimiento.
- MiniLM (22M parámetros) se sitúa en el medio, con alrededor de 13 milisegundos.
- DeBERTa (184M parámetros) tarda aproximadamente 15 milisegundos y está optimizado para la precisión.
El entrenamiento siguió un proceso de dos etapas. Los modelos se pre-entrenaron primero en UltraFeedback, un conjunto de datos público de respuestas calificadas por GPT-4, antes de ajustarlos finamente en la propia distribución de tareas de la red. La intención era dar a los jueces una comprensión de referencia amplia de la calidad antes de enfocar su atención en el contexto de puntuación específico.
El resultado principal
En un conjunto de prueba reservado de 300 ejemplos, el juez DeBERTa logró una correlación de Pearson de 0,747 con respecto al proxy de verdad fundamental, sin acceso a ninguna respuesta de referencia. Los evaluadores basados en referencias del marco anterior, que sí tenían acceso a las respuestas correctas, alcanzaron un máximo de 0,647.
La brecha tiene una explicación sencilla. Los evaluadores más antiguos eran métricas de similitud que medían la distancia del coseno con respecto a una incrustación de referencia. Los nuevos jueces fueron optimizados de extremo a extremo para la tarea de puntuación en sí. La diferencia de rendimiento refleja esa distinción más que cualquier avance arquitectónico.
Una advertencia que incluyen los autores: la verdad fundamental utilizada aquí es en sí misma un proxy: la superposición de palabras a nivel de token en lugar del juicio humano. Los jueces se correlacionan bien con esta métrica, pero si la superposición de palabras refleja de manera confiable lo que un humano consideraría una respuesta de calidad es una pregunta separada y no resuelta.
Dos características orientadas al despliegue acompañan a los jueces. Un pipeline en cascada enruta las consultas primero a través del modelo ligero y las escala a modelos más pesados solo cuando las puntuaciones son ambiguas, reduciendo los costos de evaluación hasta en un 72,7% en la configuración de umbral más agresiva, aunque la correlación cae a alrededor de 0,51 en esa configuración. Un mecanismo de calibración en línea, que funciona sin ajuste manual, identifica de forma consistente la calidad semántica como la señal dominante y ajusta los pesos en consecuencia, asignándole 4,7 veces su peso inicial con el tiempo.
Donde el sistema aún tiene dificultades
Los jueces tienen un rendimiento desigual según los tipos de tarea. En respuesta a preguntas, la correlación alcanza 0,830. En resumen, cae a 0,199. El artículo atribuye esto no a un fallo de los propios jueces, sino a la métrica de evaluación utilizada durante el entrenamiento: la superposición bruta de palabras es una medida deficiente de la calidad del resumen, por lo que los modelos entrenados con ella aprenden a rastrear una señal débil. Los autores describen esto como el principal problema abierto en lugar de una limitación conocida que se gestiona en silencio.
Ese enfoque es coherente con la forma en que el artículo presenta sus resultados en general: metódicamente, con los casos de fallo tan claramente indicados como las mejoras. Cuatro artículos en este hilo de investigación, el trabajo se lee menos como un anuncio de producto y más como un equipo que cierra brechas incrementalmente en algo que pretende desplegar realmente.
Divulgación: Este contenido es proporcionado por un tercero. Ni crypto.news ni el autor de este artículo respaldan ningún producto mencionado en esta página. Los usuarios deben realizar su propia investigación antes de tomar cualquier medida relacionada con la empresa.


También te puede interesar
Actualización de Tokenomics de Aster: Recompra y Quema del 99% de Comisiones Ya en Vivo
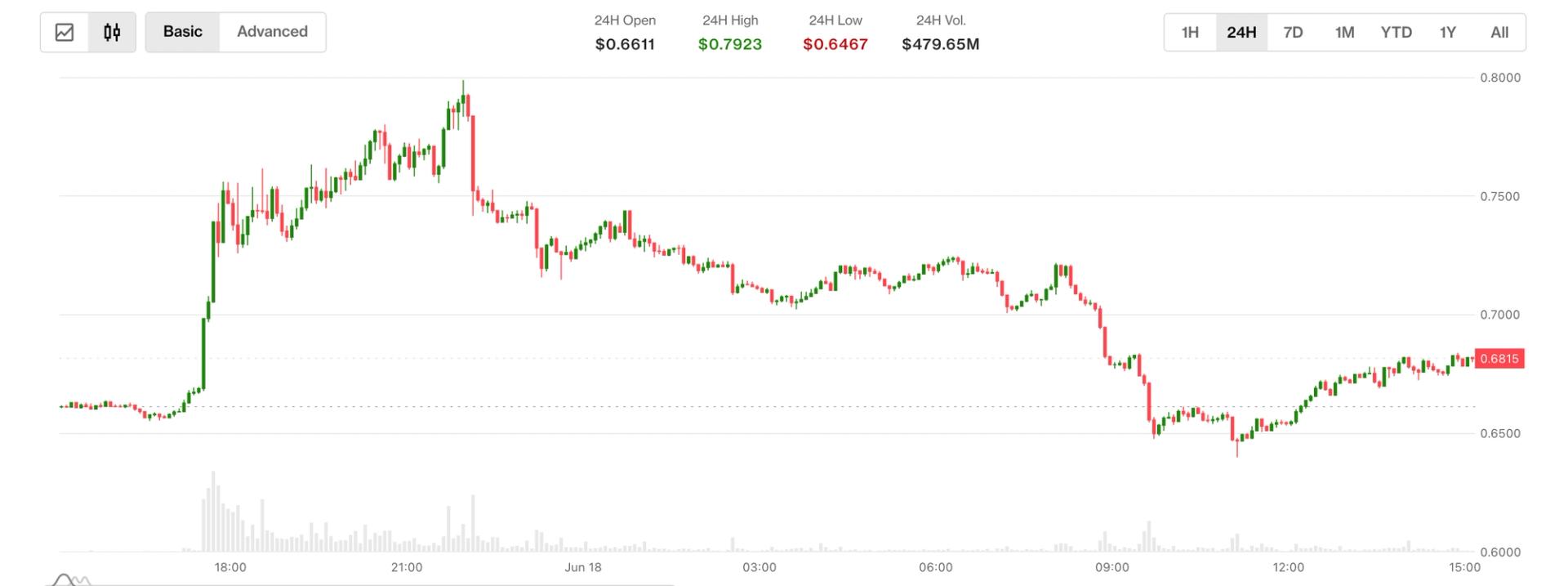
Aster subió más del 10% con la radical actualización de 'recompra y quema'. Pero las ganancias fueron efímeras

Las tensiones en los mercados energéticos son motivo de preocupación para la estabilidad financiera



